Data
Understanding ETL
 By Javier Andújar, in
By Javier Andújar, in Data
In a Bussines Intelligence project context, the ETL process is the key part. It is the means we are going to use to achieve data integration, it allows data that is localized in several sources or repositories to be unified into a single space. These data sources can be scattered across different areas within the organization, or even outside of it. The unification space for all this data in BI is typically a Data Warehouse.
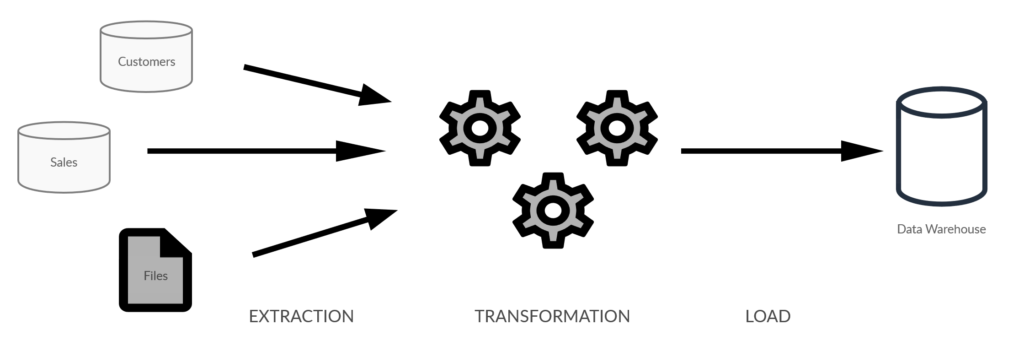
The main steps
The ETL process is divided into three main steps, as the name implies. These are: extraction of the data, transformation, and loading.
Extraction
This is the step in which we will go to the source system to consume the data that we need, we will take this data to the staging area where we can then execute the necessary transformations.
The reason for having a staging area between the source system and the Data Warehouse database is, on one hand, to impair as little as possible the performance and response time of our data source.
It should be borne in mind that our data source could be the operational transactional data base of a production system. That is why we should not execute transformations there.
On the other hand, on the other side of the process, we do not want to publish raw data to the destination database of the Data Warehouse, without having been transformed yet. That is why we need this middle space, or staging.
The sources from which you will have to extract the data can be really diverse. Some common examples include:
• ERPs
• CMRs
• Databases
• APIs
• Flat files
• CSVs
• Spreadsheets
• Web services
• Datasets
• Web scraping
• Etc.
Transformation
This is the main step of the whole process, here you work the data and give it added value, transforming it into ready-to-use information in the next steps of the BI process.
As mentioned earlier, the transformation will take place in the staging area, mainly for performance reasons.
Raw data that was extracted from the source system, in some cases need to be cleaned up, mapped to be able to relate it to other information already present in the Data Warehouse, or transformed in any other way that is necessary for the purposes being pursued in the specific BI project.
Load
The last step in the ETL process is to load the information to the target Data Warehouse database. Typically, these loads will be done in batch processes overnight, or any other time when the production systems where the information originates are less required.
Maintaining data integrity and avoiding duplication during this upload process is critical.
Usually, large amounts of data are bulk uploaded into a Data Warehouse in a short period of time, so it is important that the load of each individual ETL process is optimized for better performance.
Finally, the loading processes must be designed to be easily restarted in the event of a failure.
The right tool
Most functions of an ETL process can be achieved by programming manually, but in many cases, it is more scalable and ultimately cheaper to use a specific ETL process tool. There are numerous specific tools to develop ETL processes, each developer will have to choose the one that best suits their way of working. A good example of this kind of tools is Microsoft SQL Server Integration Services (SSIS), which allows developers to manage the flow of data from a visual environment.
Parallelize the loads
Instead of running your ETL processes one after the other, try to execute them in parallel. This is very easy to achieve using the specific tools for ETL that we mentioned previously. With this change alone you will see a significant improvement to the process. You can potentially go from a total execution time of hours for loading your Data Warehouse to just minutes.
Take only what you need
As mentioned earlier, it is important to always consider the performance of the production system from which we are extracting data. Therefore, whenever possible, our loads will be incremental. This means that from the source system we will only extract the right amount of data that we are missing in the target database of our Data Warehouse. In order to extract the necessary amount of data from the source and not one bit more, we will use some method for detecting inserts and updates, thus making sure that we are only transporting new useful data.
In specific cases where physical deletions need to be replicated, it is necessary to avoid by all means comparing the keys in the source table against the keys in the target table. Depending on the level of access we have to the source system, we will need to implement some sort of deleted business keys log. From that log we will only transport to the staging area the primary keys that have been deleted on the last day. However, having to replicate physical deletions is not a very common situation.
Spoiler Alert: It is going to fail
Since we are integrating data from systems belonging to various separate areas of the organization, or perhaps even from systems outside the organization, there are a number of things in the data sources that are beyond our control and may fail. As ETL developers we need to take this into account and be prepared to minimize the impact.
On any given day, and without any warnings, access to an API may be denied, a data type may change in the source database, the contents of a flat file may be formatted differently than expected, a network directory that we access to read spreadsheets from the accounting department can be empty, etc. You already have a good idea of the situation by now; add any other problems you can think of to the list. If we are using a web scraping technique for extraction, unexpected failures may be even more frequent.
For all this, we need to be prepared, a good practice is to configure warnings to alert both end users of the information and us when a load has failed.
Another good practice is to keep detailed logs for all the steps of the ETL processes, this will allow us to immediately identify the problem and fix it as soon as possible.