Machine Learning
How can a machine learn?
 By Javier Andújar, in
By Javier Andújar, in Machine Learning
First, let us not be so literal. We will start with a brief definition to clarify the issue:
The idea behind Machine Learning is that there are algorithms that working “independently” can “learn” about a data set and return relevant findings or conclusions obtained from that data set. We say independently because it happens without a person having to write instructions or specific codes with rules to interpret these particular data and reach conclusions. But believe me, that person will still have to be there doing a lot of other things for this to happen.
As can be seen in the Venn diagram of Data Science, Machine Learning is the conjunction of elements of computer science with other elements of mathematics and statistics.
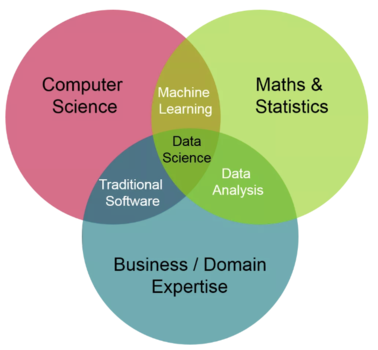
On the computer science side, Machine Learning is nourished by an important number of elements such as Big Data architectures, the ability to prepare and clean data, programming, SQL, etc. On the other hand, in terms of mathematics and statistics it takes elements of algebra, probability, statistics, and calculus.
The main objective of every learner is to develop the ability to generalize and associate.
This is achieved by creating models that generalize the information presented to them to make their predictions. And the key ingredient in this whole issue is data.
Actually, the origin and format of the data is not as relevant, since Machine Learning is capable of assimilating a wide range of these, that capability is known as Big Data. But it will not be perceived as data, but rather as a huge list of practical examples.
We could say that these algorithms are mainly divided into three categories: supervised learning, unsupervised learning, and reinforcement learning. Next, we will detail the differences between these.
Supervised learning
This type of learning is based on what is known as training information. You train the algorithm by providing it with a certain amount of data by defining it in detail with labels, also known as target variables. These labels will indicate to which target the algorithm is expected to arrive. For example, if you are looking for the algorithm to differentiate some means of transport, it will be provided with a series of photos of cars, motorcycles and bicycles with labels that define them as such.
Once a sufficient amount of data has been provided, new data can be entered without the need for labels. Based on the model that the algorithm built from the different patterns that it has been registering during training, the system will be able to differentiate between cars, motorcycles, and bicycles in the new photos. This technique is known as classification.
Another method for developing Machine Learning is to predict a continuous value, using different parameters that, combined in the introduction of new data, allow predicting a certain result. This technique is known as regression.
Unsupervised learning
True values labels or target variables are not used in this type of learning. These systems are intended to understand and abstract information patterns directly. This is a problem model known as clustering. Clustering is about grouping a set of data in such a way that data in the same group or cluster are more similar in some sense to each other than to those in other groups or clusters. It is a training method more akin to the way humans process information.
Reinforcement learning
In the reinforcement learning technique, systems learn from experience. When the algorithm makes an erroneous decision, when it reaches a conclusion that is not the expected one, it is penalized, within a scale of values. Through this method of rewards and punishments, the system restricts itself and develops a more effective way of performing its tasks.
It is a technique based on trial and error and goal-oriented algorithms that optimize the behavior of the system.