Data
Comprendiendo el ETL
 Por Javier Andújar, in
Por Javier Andújar, in Data
En un contexto de proyecto de Inteligencia de negocios, el proceso ETL es la parte clave. Es el medio que vamos a utilizar para lograr la integración de datos, permite que los datos localizados en varias fuentes o repositorios se unifiquen en un solo espacio. Estas fuentes de datos pueden estar dispersas en diferentes áreas dentro de la organización, o incluso fuera de ella. El espacio de unificación para todos estos datos en BI es típicamente un Data Warehouse.
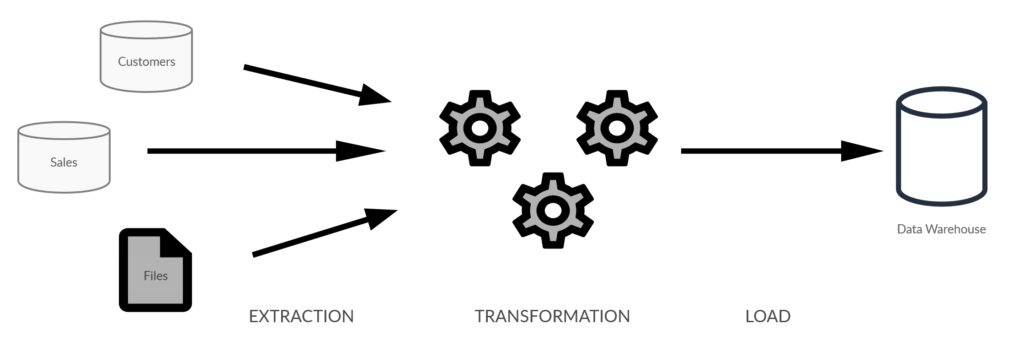
Los pasos principales
El proceso ETL se divide en tres pasos principales, como su nombre lo indica. Estos son: extracción de datos, transformación y carga.
Extracción
Este es el paso en el que iremos al sistema fuente para consumir los datos que necesitamos, llevaremos estos datos al área de preparación donde luego podremos ejecutar las transformaciones necesarias.
La razón para tener un área de preparación entre el sistema fuente y la base de datos de Data Warehouse es, por un lado, perjudicar lo menos posible el rendimiento y el tiempo de respuesta de nuestra fuente de datos.
Debe tenerse en cuenta que nuestra fuente de datos podría ser la base de datos operacionales operacionales de un sistema de producción. Es por eso que no debemos ejecutar transformaciones allí.
Por otro lado, en el otro lado del proceso, no queremos publicar datos sin procesar en la base de datos de destino del Data Warehouse, sin haber sido transformados todavía. Es por eso que necesitamos este espacio intermedio, o staging.
Las fuentes de las que tendrá que extraer los datos pueden ser muy diversas. Algunos ejemplos comunes incluyen:
• ERP
• CMR
• Bases de datos
• API
• Archivos planos
• CSV
• Hojas de cálculo
• Servicios web
• Conjuntos de datos
• Web scraping
• Etc.
Transformación
Este es el paso principal de todo el proceso, aquí trabajamos los datos y le damos valor agregado, transformándolos en información lista para usar en los próximos pasos del proceso de BI.
Como se mencionó anteriormente, la transformación tendrá lugar en el área de preparación, principalmente por razones de rendimiento.
Los datos sin procesar que se extrajeron del sistema de origen, en algunos casos necesitan ser limpiados, mapeados para poder relacionarlos con otra información ya presente en el Data Warehouse, o transformados de cualquier otra manera que sea necesaria para los propósitos que se persigan en el proyecto de BI específico.
Carga
El último paso en el proceso ETL es cargar la información en la base de datos de Data Warehouse de destino. Por lo general, estas cargas se realizarán en procesos por lotes durante la noche o en cualquier otro momento cuando los sistemas de producción donde se origina la información son menos necesarios.
Mantener la integridad de los datos y evitar la duplicación durante este proceso de carga es fundamental.
Por lo general, se cargan grandes cantidades de datos en un Data Warehouse en un corto período de tiempo, por lo que es importante que la carga de cada proceso ETL individual se optimice para un mejor rendimiento.
Finalmente, los procesos de carga deben estar diseñados para reiniciarse fácilmente en caso de falla.
La herramienta adecuada
La mayoría de las funciones de un proceso ETL se pueden lograr mediante la programación manual, pero en muchos casos, es más escalable y, en última instancia, más barato usar una herramienta de proceso ETL específica. Existen numerosas herramientas específicas para desarrollar procesos ETL, cada desarrollador tendrá que elegir la que mejor se adapte a su forma de trabajo. Un buen ejemplo de este tipo de herramientas es Microsoft SQL Server Integration Services (SSIS), que permite a los desarrolladores administrar el flujo de datos desde un entorno visual.
Paralelizar las cargas
En lugar de ejecutar sus procesos ETL uno tras otro, intente ejecutarlos en paralelo. Esto es muy fácil de lograr usando las herramientas específicas para ETL que mencionamos anteriormente. Solo con este cambio, verá una mejora significativa en el proceso. Potencialmente, puede pasar de un tiempo total de ejecución de horas para cargar su Data Warehouse a solo minutos.
Toma solo lo que necesites
Como se mencionó anteriormente, es importante considerar siempre el rendimiento del sistema de producción del que estamos extrayendo datos. Por lo tanto, siempre que sea posible, nuestras cargas serán incrementales. Esto significa que del sistema de origen solo extraeremos la cantidad correcta de datos que nos falta en la base de datos de destino de nuestro Data Warehouse. Para extraer la cantidad necesaria de datos de la fuente y no más, utilizaremos algún método para detectar inserciones y actualizaciones, asegurándonos de que solo estamos transportando nuevos datos útiles.
En casos específicos donde las eliminaciones físicas necesitan ser replicadas, es necesario evitar por todos los medios comparar las claves en la tabla de origen con las claves en la tabla de destino. Dependiendo del nivel de acceso que tengamos al sistema de origen, necesitaremos implementar algún tipo de registro de claves de negocio eliminadas. Desde ese registro solo transportaremos al área de preparación las claves principales que se han eliminado el último día. Sin embargo, tener que replicar eliminaciones físicas no es una situación muy común.
Alerta de Spoiler: va a fallar
Dado que estamos integrando datos de sistemas que pertenecen a varias áreas separadas de la organización, o tal vez incluso de sistemas fuera de la organización, hay una serie de cosas en las fuentes de datos que están fuera de nuestro control y pueden fallar. Como desarrolladores de ETL, debemos tener esto en cuenta y estar preparados para minimizar el impacto.
En cualquier día, y sin advertencias, puede resultar denegado el acceso a una API, puede cambiar un tipo de datos en la base de datos de origen, el contenido de un archivo plano puede formatearse de manera diferente a la esperada, un directorio de red al que accedemos para leer hojas de cálculo del departamento de contabilidad puede amanecer vacío, etc. Ya tiene una buena idea de la situación; agregue cualquier otro problema que se le ocurra a la lista. Si estamos utilizando una técnica de web scraping para la extracción, las fallas inesperadas pueden ser aún más frecuentes.
Para todo esto, debemos estar preparados, una buena práctica es configurar advertencias para alertar tanto a los usuarios finales de la información como a nosotros cuando falle una carga.
Otra buena práctica es mantener registros detallados de todos los pasos del proceso ETL, esto nos permitirá identificar de inmediato el problema y solucionarlo lo antes posible.