Machine Learning
¿Cómo puede aprender una máquina?
 Por Javier Andújar, in
Por Javier Andújar, in Machine Learning
Primero, no seamos tan literales. Comenzaremos con una breve definición para aclarar el asunto:
La idea detrás del aprendizaje automático o Machine Learning es que existen algoritmos que funcionan de manera “independiente” y pueden “aprender” sobre un conjunto de datos y devolver hallazgos o conclusiones relevantes obtenidos de ese conjunto de datos. Decimos independientemente porque sucede sin que una persona tenga que escribir instrucciones o códigos específicos con reglas para interpretar estos datos en particular y llegar a conclusiones. Pero créanme, esa persona todavía tendrá que estar allí haciendo mucho trabajo para que esto suceda.
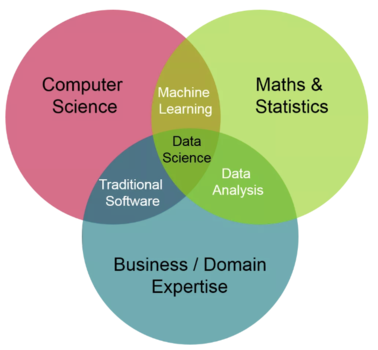
Como se puede ver en el diagrama de Venn de Data Science, Machine Learning es la conjunción de elementos de la informática con otros elementos de las matemáticas y las estadísticas.
Por el lado de la informática, el aprendizaje automático se nutre de una cantidad importante de elementos, como las arquitecturas de Big Data, la capacidad de preparar y limpiar datos, programación, SQL, etc. Por otro lado, en términos de matemática y estadística, toma elementos de álgebra, probabilidad, estadística y cálculo.
El objetivo principal de cada learner es desarrollar la capacidad de generalizar y asociar.
Esto se logra creando modelos que generalizan la información que se les presenta para hacer sus predicciones. Y el ingrediente clave en todo esto son los datos.
En realidad, el origen y el formato de los datos no son tan relevantes, ya que Machine Learning es capaz de asimilar una amplia gama de estos, esa capacidad se conoce como Big Data. Pero no se percibirá como datos, sino como una gran lista de ejemplos prácticos.
Podríamos decir que estos algoritmos se dividen principalmente en tres categorías: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje de refuerzo. A continuación, detallaremos las diferencias entre estos.
Aprendizaje supervisado
Este tipo de aprendizaje se basa en lo que se conoce como información de capacitación. Usted entrena el algoritmo proporcionándole cierta cantidad de datos definiéndolo en detalle con etiquetas, también conocidas como variables objetivo. Estas etiquetas indicarán a qué destino se espera que llegue el algoritmo. Por ejemplo, si está buscando el algoritmo para diferenciar algunos medios de transporte, se le proporcionará una serie de fotos de automóviles, motocicletas y bicicletas con etiquetas que los definen como tales.
Una vez que se ha proporcionado una cantidad suficiente de datos, se pueden ingresar nuevos datos sin necesidad de etiquetas. Basado en el modelo que el algoritmo construyó a partir de los diferentes patrones que ha estado registrando durante el entrenamiento, el sistema podrá diferenciar entre automóviles, motocicletas y bicicletas en las nuevas fotos. Esta técnica se conoce como clasificación.
Otro método para desarrollar Machine Learning es predecir un valor continuo, utilizando diferentes parámetros que, combinados en la introducción de nuevos datos, permiten predecir un cierto resultado numérico. Esta técnica se conoce como regresión.
Aprendizaje no supervisado
Las etiquetas de valores verdaderos o las variables objetivo no se usan en este tipo de aprendizaje. Estos sistemas están destinados a comprender y abstraer patrones de información directamente. Este es un modelo de problema conocido como agrupación. La agrupación se trata de agrupar un conjunto de datos de tal manera que los datos en el mismo grupo o agrupación sean más similares entre sí que con los de otros grupos o agrupaciones. Es un método de entrenamiento más similar a la forma en que los humanos procesan la información.
Aprendizaje reforzado
En la técnica de aprendizaje por refuerzo, los sistemas aprenden de la experiencia. Cuando el algoritmo toma una decisión errónea, cuando llega a una conclusión que no es la esperada, se penaliza, dentro de una escala de valores. Mediante este método de recompensas y castigos, el sistema se restringe y desarrolla una forma más efectiva de realizar sus tareas.
Es una técnica basada en prueba y error y algoritmos orientados a objetivos que optimizan el comportamiento del sistema.