Data
Extracción de datos de una fuente web utilizando Python + Pandas
 Por Javier Andújar, in
Por Javier Andújar, in Data
Para el siguiente ejemplo vamos a utilizar Python con Pandas en un entorno Windows para hacer una carga diaria en una base de datos SQL Server desde una fuente web. Supongamos que queremos obtener información sobre la actual pandemia de COVID-19, tal vez porque queremos representar el riesgo de contagio que implica visitar los diferentes países, así que un buen punto de partida sería conseguir algún conjunto de datos que muestre cantidad de contagios discriminados por regiones geográficas. Un buen lugar para buscar conjuntos de datos es el Dataset Search de Google (https://datasetsearch.research.google.com/), que fue lanzado en 2018 y el pasado 23 de enero del 2020 dejó de ser beta.
El conjunto de datos
Recorriendo la web hemos llegado hasta el repositorio de datos que comparte en GitHub el Centro de Ciencias de Sistemas en Ingeniería de la Universidad Johns Hopkins, JHU CSSE COVID-19 Data, en https://github.com/CSSEGISandData/COVID-19. Al final de la página podemos leer que está compartido bajo licencia Creative Commons Attribution 4.0 International (CC BY 4.0), o sea que podemos utilizarlo siempre y cuando hagamos la correspondiente atribución a la fuente, tal como se describe en el punto dos de los términos de uso. El origen es lo suficientemente confiable y parecen tener la información que necesitamos, así que vamos a descargar el archivo y a analizarlo un poco.
Dentro de todos los conjuntos de datos que hay en ese repositorio, el que serviría para nuestro propósito es time_series_covid19_confirmed_global, un archivo en formato csv que contiene todos los contagios confirmados a nivel global. El archivo no es grande, a la fecha pesa 263KB. Vamos a abrirlo para hacer un primer reconocimiento de los datos y la estructura:
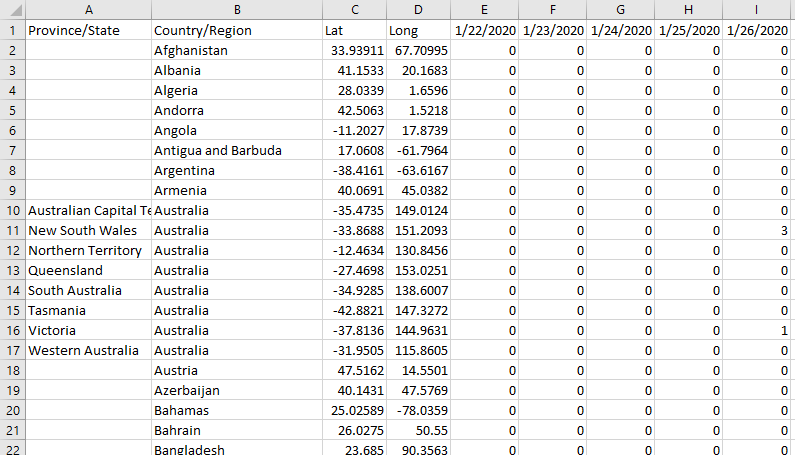
A primera vista notamos que tenemos un problema de formato: hay una fila por cada zona geográfica y la cantidad de casos se presentan en sucesivas columnas, se agrega una nueva columna por cada día. Esta estructura no va a servir para nuestra base, porque no queremos agregar una nueva columna en cada carga. Más adelante tendremos que ejecutar alguna transformación para darle a los datos la estructura que queremos, para eso utilizaremos Pandas. Fuera de esto, no se encuentra mayor inconveniente en el conjunto de datos, está muy prolijo y no hay basura para limpiar. Además de provincia/estado, país/región, vemos que incluyeron los datos de latitud y longitud, esto va a ser importante más adelante si queremos representar la información sobre un mapa, así que vamos a cargar estos dos datos también en nuestra base.
La estructura de destino
En la base COVID-19, que generamos para este ejercicio, vamos a crear una tabla que pueda albergar la información del conjunto de datos que acabamos de explorar:
USE [COVID-19] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [stg].[JHUConfirmedGlobal]( [ProvinceState] [varchar](100) NOT NULL, [CountryRegion] [varchar](100) NOT NULL, [Lat] [float] NULL, [Long] [float] NULL, [Date] [date] NOT NULL, [Value] [int] NULL, PRIMARY KEY CLUSTERED ( [CountryRegion] ASC, [ProvinceState] ASC, [Date] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY] ) ON [PRIMARY] GO
Estoy creando la tabla en el esquema stg (staging), por si luego fuera necesario trabajar un poco más los datos en la base antes de ser consumidos por una aplicación o reporte.
El proceso de carga
Para tomar la información del repositorio vamos a utilizar Python y en algún punto tendremos que usar Pandas también para despivotar los datos que nos llegan como columnas y pasarlos a filas. Pandas es una biblioteca que ofrece una gran cantidad de herramientas para trabajar con estructuras y hacer manipulación de datos dentro de Python.
Para empezar, vamos a necesitar las siguientes librerías:
import os import requests import pyodbc as odbc import csv import pandas as pd
- os: para utilizar ciertas funcionalidades del sistema operativo a la hora de manipular archivos.
- requests: para descargar el conjunto de datos.
- pyodbc: para conectar al SQL Server.
- csv: para leer el archivo separado por comas.
- pandas: para despivotar (convertir columnas en filas) los datos de cada fecha.
El resto del código se verá así:
sql_conn = odbc.connect('DRIVER={ODBC Driver 17 for SQL Server}; SERVER=*******; DATABASE=COVID-19; Trusted_Connection=yes')
url='https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv'
response = requests.get(url)
with open(os.path.join("C:\Covid-19 Data Proyect\RawData", "time_series_covid19_confirmed_global.csv"), 'wb') as f:
f.write(response.content)
pd_data = pd.read_csv (r'C:\Covid-19 Data Proyect\RawData\time_series_covid19_confirmed_global.csv', encoding='utf-8')
pd_unpivoted_data = pd.melt(pd_data,id_vars=['Province/State','Country/Region','Lat','Long'], var_name='Date', value_name='Value')
pd_unpivoted_data.to_csv(r'C:\Covid-19 Data Proyect\RawData\time_series_covid19_confirmed_global_UNPIVOT.csv')
unpivoted_file = open('C:/Covid-19 Data Proyect/RawData/time_series_covid19_confirmed_global_UNPIVOT.csv','r', encoding='utf-8')
unpivoted_data = csv.reader(unpivoted_file, delimiter=',')
next(unpivoted_data)
sql_conn.execute('Truncate table stg.JHUConfirmedGlobal')
sql_conn.commit()
for row in unpivoted_data:
sql="""INSERT INTO stg.JHUConfirmedGlobal ([ProvinceState], [CountryRegion], Lat, Long, Date, Value)
values('"""+row[1].replace("'","´")+"""','"""+row[2].replace("'","´")+"""',"""+row[3]+""","""+row[4]+""",'"""+row[5]+"""',"""+row[6]+""")"""
print(sql)
sql_conn.execute(sql)
sql_conn.commit()
sql_conn.execute('exec stg.spNextProcess')
sql_conn.commit()
unpivoted_file.close()
sql_conn.close()
Este sería un ejemplo básico que podríamos utilizar. Al principio descargamos el archivo y luego creamos otro archivo despivotado, podríamos eliminar los archivos luego de utilizarlos, pero en este ejemplo suponemos que queremos conservar un histórico de los originales en la carpeta RawData, ya que pesan poco y es útil poder ver qué fue lo que cargamos en caso de surgir algún error. Además, en la documentación del repositorio se aclara que se podrán hacer correcciones retroactivas a los datos, otro buen motivo para guardar los originales de cada día ya que nos permitirá hacer futuras comparaciones. Sabiendo que los datos pueden ser corregidos, el siguiente paso es truncar la tabla de destino, stg.JHUConfirmedGlobal, ya que vamos a hacer una carga completa en vez de quedarnos solo con las novedades de la fecha. Luego viene el loop de inserciones. Finalmente, y si fuera necesario, podemos disparar cualquier cálculo o movimiento de datos que fuera necesario dentro de la base. En el ejemplo esto se hará dentro del stored procedure stg.spNextProcess.
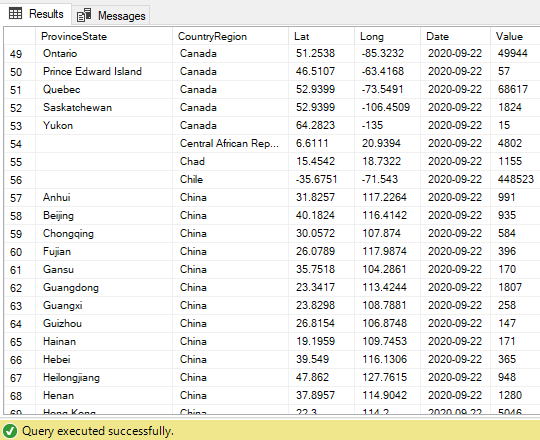
El resultado final se verá así. Las columnas Date y Value ahora contienen los datos de las filas despivotadas:
Programando la ejecución del proceso
Supongamos que queremos hacer que la carga se ejecute todos los días una vez al día, y que esto suceda temprano en la mañana. Podría ser a las 8 am, para asegurarnos que a las 9 am todo el mundo esté trabajando con datos actualizados. ¿Cómo conseguimos esto? Hay varias maneras de hacerlo:
La primera opción que se nos viene a la cabeza a los usuarios de SQL Server es crear un Job del Agent. Para esto vamos a abrir el Management Studio (SSMS) y en el Object Explorer vamos a ir a SQL Server Agent, Jobs, click derecho New Job.
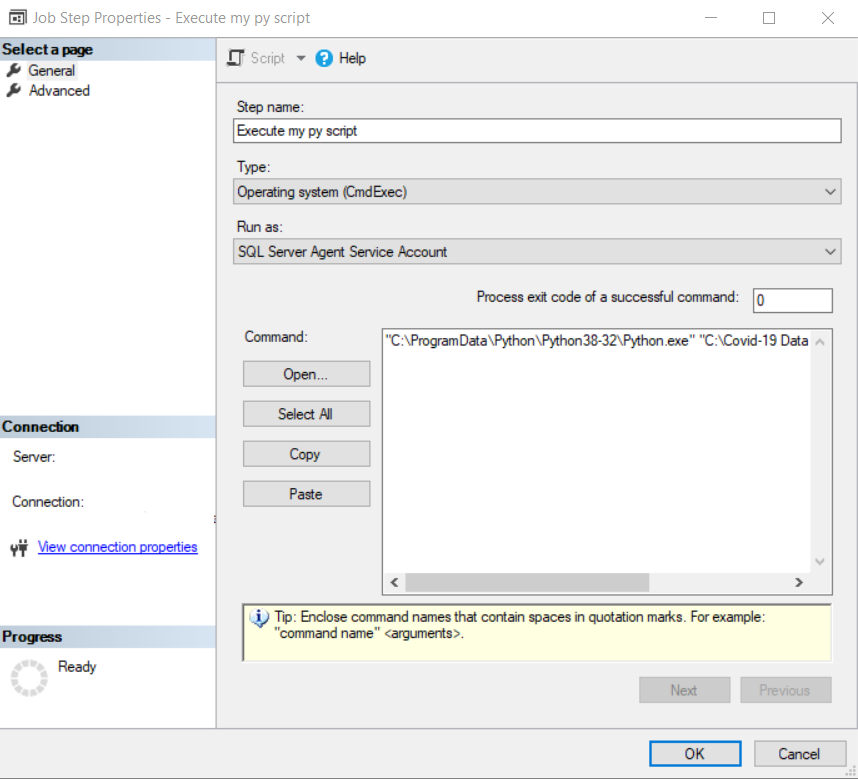
En el job vamos a crear un step que sea de tipo Operating system (CmdExec) y en Command vamos a poner “C:\ProgramData\Python\Python38-32\Python.exe” “C:\Covid-19 Data Proyect\p01_load_confirmed_world.py” con el path y el nombre de script que ustedes hayan creado.
Por último, en la opción Schedules vamos a seleccionar la que queramos usar, o vamos a crear una nueva para las 8 am con las siguientes opciones:
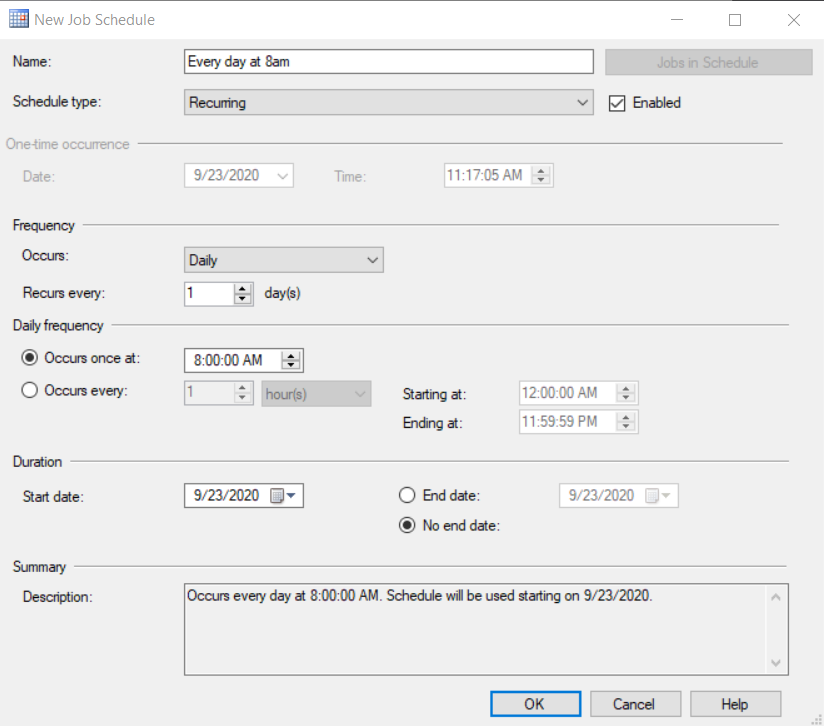
Por supuesto que hay otras herramientas de scheduling si no disponemos de SQL Server. Un script de Python se puede ejecutar también desde el Task Scheduler de Windows o desde cualquier otra herramienta de scheduling de procesos como ControlM.
Con este último paso hemos completado el desarrollo de la carga diaria. De aquí en adelante solo resta determinar cómo vamos a utilizar la información obtenida para que le resulte útil a los usuarios.